I made a local LLM work on my Windows PC, using (for now still) free software, and no Docker. As simple and idiot-friendly as it gets.
DeepSeek wrote a well-functioning WordPress website scraper, so I could feed all my public knowledge (from my websites) – along with my private Deathnotes.
So far – so good (says a man while falling off a 10-storey building).
The basic setup – TL/DR
My PC configuration
Here are the specs of the PC I am using for this project:
https://www.bikegremlin.net/threads/my-2022-2024-pc-build-overview.411/
Software setup
- LM Studio to run my LLM model.
- AnythingLLM to save my knowledgebase to the model and serve as an interface for any chats (prompts).
- All my articles and Deathnotes scraped and imported as .txt/.md format.
🧱 PHASE 1: Install LM Studio + Download Nous Hermes 2 – Mistral 13B
Setting up offline LLM brain, by installing:
- LM Studio (for Windows).
https://lmstudio.ai/ - Nous Hermes 2 – Mistral 13B model in GGUF format, quantized to Q5_K_M.
✅ STEP 1.1 – Download & Install LM Studio
- Go to:
👉 https://lmstudio.ai - Click “Download for Windows”
(it’s a standard.exeinstaller, ~300 MB) - Install the app like any regular Windows program.
- After install, run LM Studio.
✅ STEP 1.2 – Download Nous Hermes 2 – Mistral 13B (GGUF)
I created a directory for LLMs on my working drive:
D:\ai-llm\
I configured the LM Studio to use that directory for storing models:
My Models -> Models Directory -> […] -> Change
Select: D:\ai-llm\
Then:
- In LM Studio, go to the “Models” tab
- In the search bar, type:
Nous-Hermes-13B-Q5-K-M-Profiles - Let it download.
- Once the download is finished, click “Load Model“.
Stupid software wouldn’t let me use a previously downloaded .gguf file (or I’m too stupid to figure out how to “add” it to the software.
After decades of pro IT work, I could not figure it out! UI is shit. FACT.
Download links:
https://huggingface.co/TheBloke/Nous-Hermes-13B-GGUF
https://huggingface.co/TheBloke/Nous-Hermes-13B-GGUF/resolve/main/Nous-Hermes-13B.Q5_K_M.gguf
✅ STEP 1.3 – Verify & Run the Model
I went to the chat tab and this was my very first local LLM prompt… ready? 🙂
English breakfast. 🙂
Of course, the model gave me the recipe – still not into my wacky brain and references. Oh well… 🙂
1.4. Problems – as usual LOL
LM Studio should be listening on:
http://localhost:1234/v1/
But… that was not the case. I had to right click the system tray icon and click: “Start server on port 1234“. Yes.
Enabling it in the app’s options under Settings/Developer/
checking “Enable Local LLM Service” checkbox was not enough. Sigh.
🔧 Phase 2: Set up AnythingLLM to ingest my data
AnythingLLM handles:
- Reading my files.
- Chunking the content.
- Creating embeddings.
- Running a chat UI connected to my local LLM (LM Studio).
✅ Step 2.1: Install AnythingLLM (no Docker, clean install)
Installation download page (v1.8.1-r2 at the time of writing):
https://anythingllm.com/desktop
Since the application is unsigned, Windows Defender flags it as unrecognized, so I had to:
- Click on “More info”.
- Then click “Run anyway”.
Then I went through the usual Microsoft bullshit “[Browse Microsoft Store] [Install anyway]” buttons. Sigh.
After installation, I chose the “Service to handle the chatting” – LM Studio in my case. Options there (all set by default after auto-detect):
- LM Studio Base URL – autodetect worked (http://127.0.0.1:1234/v1).
- LM Studio Model – nous-hermes-13b-k-m-profiles
- Max Tokens – 4096
Workspaces name: LLM-Deathnotes 🙂
I created a directory:
D:\ai-llm\anythingllm-data\
Leave the embeding option with AnythingLLM Embedder!
⚙️ Step 2.2: Configure the scraper
Figure out how to scrape my websites, and parse it to my local LLM.
For start, I went to settings -> Text Splitter & Chunking ->
Tecth Chunk Size: 1000
Text Chunk Overlap: 200
That should work for the LLM I installed and configured (unless Google is lying more than usually).
Everybody wants to fuck you, everybody wants your money (or at least “just” your data). Fuck.
Relja Novović – frustrated by the state of available tools
Note:
ChatGPT was useless for this task (struggled with the rest, but for this it was outright misleading).
DeepSeek – less bad in this case.
Run command prompt:
pip install requests beautifulsoup4 tqdm
python.exe -m pip install --upgrade pipRun Python to scrape the site (code written by DeepSeek):
import requests
from bs4 import BeautifulSoup
import xml.etree.ElementTree as ET
from urllib.parse import urlparse
import os
import time
import re
# Configuration - example.com specific
SITEMAP_URL = "https://www.example.com/sitemap.xml"
OUTPUT_DIR = r"D:\localdir-scrape" # Using raw string for Windows path
DELAY_SECONDS = 0.8 # Slightly faster while being respectful to server
USER_AGENT = "Content-Scraper/1.0 (https://www.example.com; [email protected])"
MAX_RETRIES = 3 # Retry failed requests
os.makedirs(OUTPUT_DIR, exist_ok=True)
def get_urls_from_sitemap(sitemap_url):
"""Extract all URLs from sitemap.xml"""
urls = []
try:
response = requests.get(sitemap_url, headers={"User-Agent": USER_AGENT})
root = ET.fromstring(response.content)
# Find all URL locations
for url in root.findall(".//{*}loc"):
urls.append(url.text)
except Exception as e:
print(f"Error parsing sitemap: {e}")
return urls
def clean_content(soup):
"""Optimized cleaner for WordPress structure"""
# Remove known non-content elements
selectors_to_remove = [
'nav', 'header', 'footer', 'aside', # Standard WP areas
'.easy-toc', # Easy Table of Contents container
'.post-navigation', # Post navigation
'#comments', # Comments section
'.sidebar', '.widget-area', # Sidebar widgets
'.generate-back-to-top', # Back to top button
'.entry-meta', '.post-meta', # Post meta (date, author)
'.shared-counts-wrap', # Share buttons
'.related-posts', '.yarpp', # Related posts
'.wp-block-buttons', # Button groups
'#cookie-notice', # Cookie notice
'.ad-container', # Ads
'.generate-page-header', # Page header
'.generate-columns-container', # Columns (often non-content)
'form', # Forms
'iframe', # Embeds
]
for selector in selectors_to_remove:
for element in soup.select(selector):
element.decompose()
# Target main content area - website specific
main_content = soup.select_one('.entry-content, .main-content, .inside-article')
if main_content:
# Remove empty paragraphs
for p in main_content.find_all('p'):
if not p.text.strip():
p.decompose()
return main_content.get_text(separator="\n", strip=True)
else:
return soup.get_text(separator="\n", strip=True)
def sanitize_filename(title):
"""Create safe filenames from titles"""
# Remove special characters and truncate
clean_title = re.sub(r'[^\w\s-]', '', title).strip().replace(' ', '_')
return clean_title[:100] + ".txt"
def scrape_page(url):
for attempt in range(MAX_RETRIES):
try:
response = requests.get(
url,
headers={"User-Agent": USER_AGENT},
timeout=15
)
soup = BeautifulSoup(response.content, 'html.parser')
# Extract title for filename
title = soup.title.string if soup.title else urlparse(url).path
filename = sanitize_filename(title)
filepath = os.path.join(OUTPUT_DIR, filename)
# Clean and extract content
content = clean_content(soup)
# Write to file
with open(filepath, 'w', encoding='utf-8') as f:
f.write(f"URL: {url}\n")
f.write(f"Title: {title}\n\n")
f.write(content)
print(f"✅ Saved: {filename}")
return True
except Exception as e:
print(f"⚠️ Attempt {attempt+1} failed for {url}: {e}")
time.sleep(2) # Wait longer between retries
return False
# Step 1: Get all URLs from sitemap
print(f"🚀 Fetching sitemap from {SITEMAP_URL}")
urls = get_urls_from_sitemap(SITEMAP_URL)
print(f"📄 Found {len(urls)} URLs in sitemap")
# Step 2: Scrape each page
success_count = 0
for i, url in enumerate(urls):
print(f"\n🌐 Scraping ({i+1}/{len(urls)}): {url}")
if scrape_page(url):
success_count += 1
time.sleep(DELAY_SECONDS) # Be polite to the server
print(f"\n✅ Scraping complete! Success rate: {success_count}/{len(urls)}")
print(f"📁 Files saved to: {OUTPUT_DIR}")Now, I had to manually add files using the interface. Then click “Save and embed.”
Copy/pasting over 200 articles at a time did not take too long!
You can also just drag & drop the whole directory where the files are saved.
2.3. A simple(r) solution? Nope!
I saw the Bulk Link Scraper – it is on the “Data Connectors” tab of the documents upload page! However, it is not working very well in practice. Useless.
🧠 This Setup = 3 Simple Layers (how it works)
| Layer | Tool | Role |
|---|---|---|
| Engine | LM Studio | Runs the LLM (Hermes 2) and answers prompts |
| Brain (memory) | AnythingLLM | Stores the knowledge as vector embeddings (chunks of your .txt/.md/docs) |
| Interface | AnythingLLM Web UI | Where you type questions and get responses |
3.1. 🔄 How it works when you ask a question:
- You ask a question in AnythingLLM’s chat UI
- AnythingLLM:
- Searches your ingested files using a vector database (Chroma or similar)
- Finds the top matching chunks (usually 10–20)
- It builds a new prompt:
- Your question + those relevant chunks
- It sends that prompt to LM Studio, which runs your model (Hermes 2)
- LM Studio returns a response
- AnythingLLM displays it (with source citations if enabled)
3.2. ✅ Visual Summary
You
↓
AnythingLLM Chat UI
↓
(Search your documents using vector embeddings)
↓
Build contextual prompt
↓
LM Studio (runs Hermes 2)
↓
Answer
↓
You
3.3. ✅ TL/DR:
LM Studio = your LLM engine
AnythingLLM = memory, search, and interface
Now, I could also:
- Add a second model (and have one for fast answers, one for depth).
- Auto-launch both together.
- Run multiple workspaces for different domains (e.g. bikes vs hosting).
4. BACKUPS
I know, important, we must do them regularly, yeah!
I can copy the raw file and model storage directory:
D:\ai-llm\
D:\ai-llm\anythingllm-data\
For users of the desktop version, your AnythingLLM database and data is stored locally. Here’s where you can find it (documentation):
- Windows:
C:\Users\<YourUsername>\AppData\Roaming\anythingllm-desktop\storage - macOS:
/Users/<YourUsername>/Library/Application Support/anythingllm-desktop/storage - Linux:
~/.config/anythingllm-desktop/storage/
anythingllm.db: The main SQLite database.lancedb/: Contains your local vector database.documents/: Parsed content from uploaded files.vector-cache/: Cached embeddings of documents.models/: Stored LLMs or embedder models.plugins/: Custom agent skills.
To back up your data, you can copy the entire storage directory to a secure location. Restoring involves replacing the existing storage folder with your backup. You must close the AnythingLLM before trying to archive this on Windows!
5. My experience
This is a work in progress – and this is probably the most messy article I’ve published – even if half of it is AI-written (my idea is to help myself – and others – keeping this as a note, to fix and update as I go).
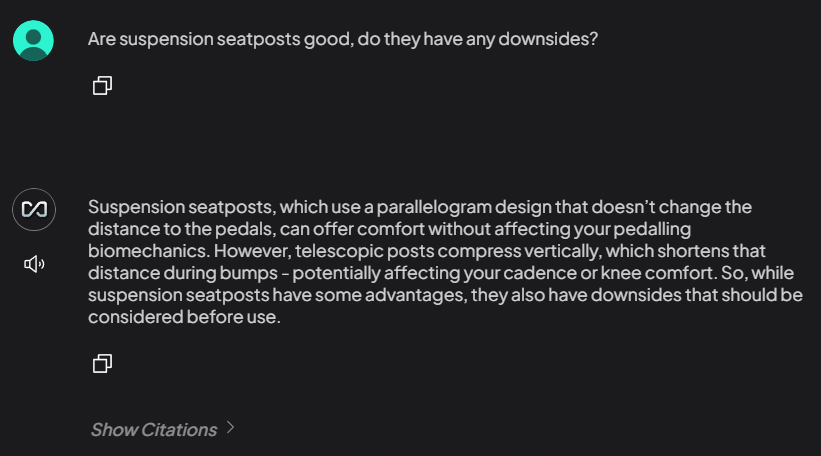
Here is an example of an answer I got from my system:
The second example is more impressive, and I’ll explain why:
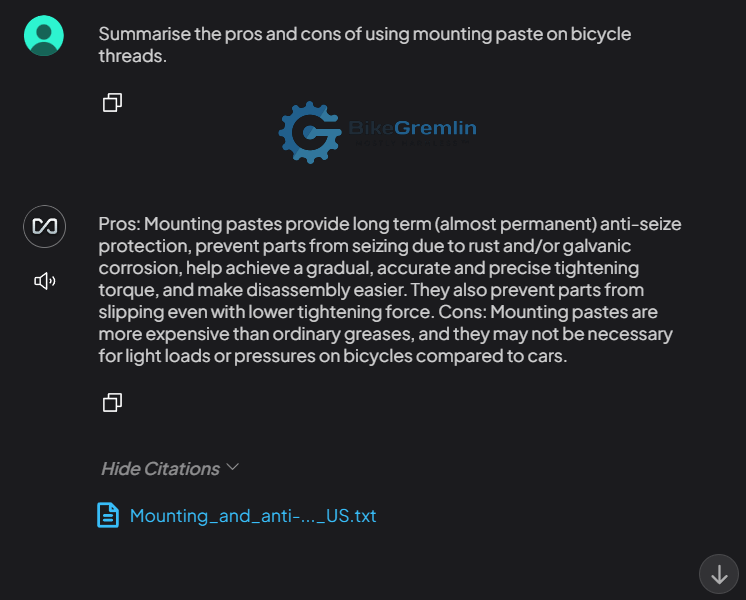
Why is this impressive? Because I’m a huge fan of anti-seize mounting pastes and use them on practically every bolt! 🙂 However, my notes and articles are fucking objective (LOL). So, what the “robot” answered is in fact correct, even if I don’t like or follow that answer (I always err to the side of caution and use anti-seize). This is actually very good, and perhaps even more correct than I would answer, because I would have recommended anti-seize a bit more “aggressively” so to speak.
Why?
I don’t suppose any folks who “just skim it” will reach this far – or stop to think for that matter. Why did I bother with this? Why didn’t I just use ChatGPT?
There are several reasons:
- Privacy and ethical reasons
Some things should be kept offline, encrypted.
This info remains offline, and I can use simple .txt files to add more. - Freedom of thought
ChatGPT and all the other popular corporate-owned platforms are prone to censorship! Their owners control what I can find (just like Google). - Information and data reliability
ChatGPT and other popular LLMs often give faulty information.
My model uses information that I have written and verified – so it is something I can trust. Like steel. 🙂 - Long-term memory – with my data
Related to the point above. Public LLMs forget everything after the chat ends (even if you let them track you). Some can save a minimal amount of data, but not all my articles and offline notes – that is waaay over their limit. My local offline “private LLM/AI” lets me build a persistent memory – based entirely on my own notes, articles, and files. No training required, no cloud sync, just structured local storage I control.
Last updated:
Originally published: